

1814
0
KEGG
KEGG 是了解高级功能和生物系统(如细胞、 生物和生态系统),从分子水平信息,尤其是大型分子数据集生成的基因组测序和其他高通量实验技术的实用程序数据库资源, 由日本京都大学生物信息学中心的Kanehisa实验室于1995年建立,是国际最常用的生物信息数据库之一。
推荐指数:
详细信息
KEGG 是了解高级功能和生物系统(如细胞、 生物和生态系统),从分子水平信息,尤其是大型分子数据集生成的基因组测序和其他高通量实验技术的实用程序数据库资源, 由日本京都大学生物信息学中心的Kanehisa实验室于1995年建立,是国际最常用的生物信息数据库之一。KEGG是一个整合了基因组、化学和系统功能信息的数据库。把从已经完整测序的基因组中得到的基因目录与更高级别的细胞、物种和生态系统水平的系统功能关联起来是KEGG数据库的特色之一。
KEGG查询指南
1.KEGG数据库的基本构成
整合了基因组、化学和系统功能信息的综合性数据库
大致分为系统信息、基因组信息、化学信息和健康信息四大类
查询代谢途径、酶、基因、产物等,BLAST查询未知序列的代谢途径信息
2.KEGG常用子数据库
PATHWAY(代谢途径数据库) 查询各种代谢途径
BRITE(代谢通路及同源基因数据库) 查询酶和底物之间的关系,查询某种酶的同源基因
GENES(基因数据库) 查询不同的基因或基因组的信息
LIGAND(配体数据库) 查询反映猴子那个各种化合物的信息
KEGG Organisms列出各物种的代码、KEGG使用三个英文小写字母代表各个物种
3.KEGG数据库模型
KEGG 模型是作为集成数据库资源实现的,该资源由 16 个数据库组成,如下所示。它们大致分为系统信息、基因组信息、化学信息和健康信息,它们通过网页的颜色编码来区分。
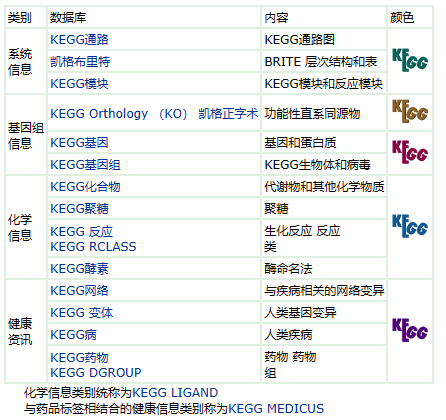
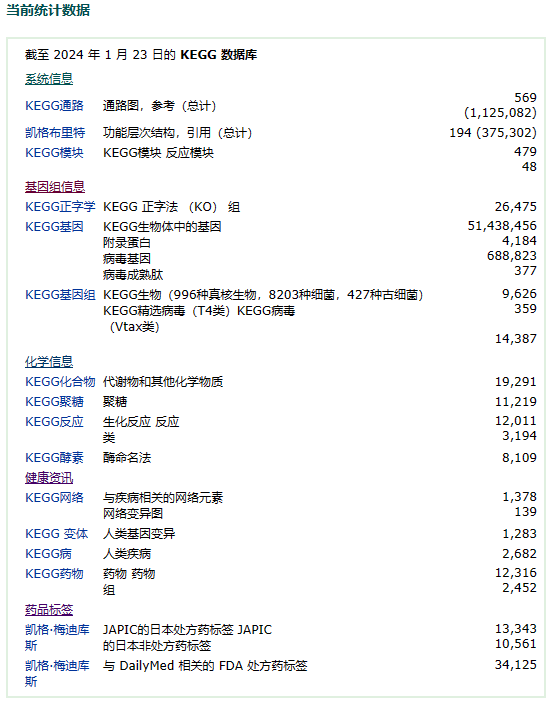
4.KEGG数据库体量
随机推荐